Queuing theory is the mathematical study and modeling of waiting times in lines (also called queues). It is used to predict queue length and waiting time in simulations. Its goal is to inform business decisions that improve queue speed to optimize resource planning, space allocation, and related tasks.
Queuing theory studies not only customers but also products, raw materials, services, and projects. Anywhere lines form—whether in a retail store, a shipping center, or an assembly line—queuing theory applies.
Agner Krarup Erlang posed the first queuing theory problem in 1908, when he studied how large a telephone exchange needed to be to minimize the number of calls not connected because the exchange was busy.
Today, managers use queuing theory to address a range of challenges. It figures prominently in Lean Six Sigma solutions. In this article, we’ll summarize queuing theory, exploring:
- How queuing theory works
- Queuing process components
- Queue disciplines
- Service process
How queuing theory works
Queues can occur whenever resources are limited. The concept of queuing is strictly connected to the demand and capacity. The figure below shows demand relative to capacity.
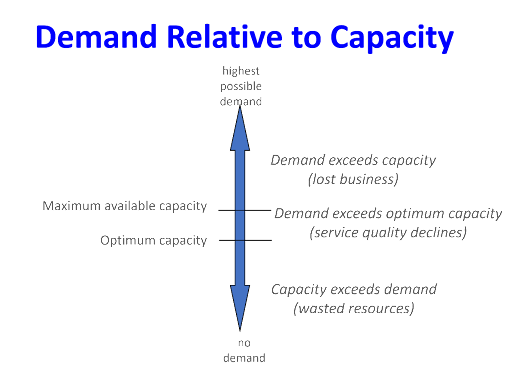
When capacity exceeds demand, resources are wasted. When demand exceeds capacity, business is lost. Queuing theory seeks to determine the optimum capacity and the maximum available capacity before service quality starts to decline. It seeks to design balanced systems that serve customers quickly and efficiently in a sustainable manner.
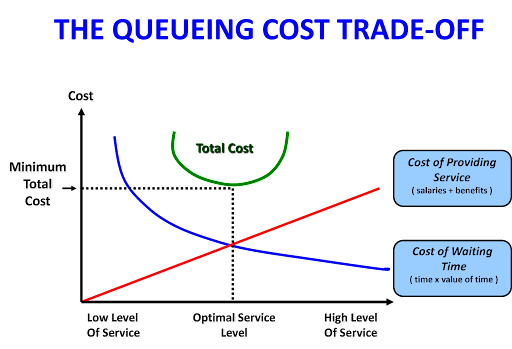
The graph below illustrates the queuing cost trade-off that drives the quest for optimum service level ( the percentage of services that can be delivered at the time desired by the customer) at the minimum cost.
<
Queuing process components
Figure 3 illustrates the components of a basic queuing process.
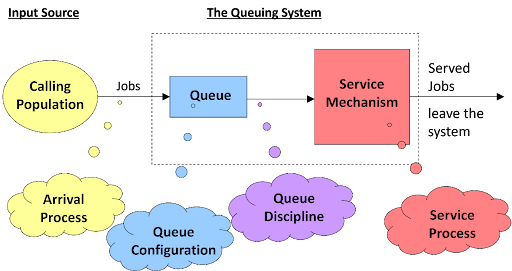
Definition of terms
- The calling population is the grouping from which customers/jobs originate. The size can be finite or infinite (the latter is most common), homogeneous (only one type of customers/ jobs) or heterogeneous (several different kinds of customers/jobs).
- The arrival process determines how, when and where customer/jobs arrive to the system. Critical characteristics include the customers’/jobs’ inter-arrival times and how the customer arrivals are distributed in time. Correctly specifying the arrival process requires data collection of interarrival times and statistical analysis. The simplest arrival process involves regular arrivals (i.e., the same constant time interval between successive arrivals). A Poisson stream of arrival corresponds to arrivals at random.
- The queue configuration specifies the number of queues. Factors include the number of lines, the number of service stations, the location of both and their effect on customer behavior, and the maximum number of jobs the queue can accommodate.
- Service mechanism indicates the manner in which customers receive service once they have reached the front of the queue. Service mechanisms are typically categorized as single-server or multi-server systems.
Queue behaviors
- Balking refers to customers who arrive but refuse to join the waiting line because it is too long to suit their needs or interests.
- Reneging customers are those who enter the queue but then become impatient and leave without completing their transaction.
- Jockeying describes when customers change line in an effort to join the fastest-moving queue.
Queue types
- Multiple queues: Customers form more than one line and may decide which line to join; they may switch if they wish. Multiple queues accommodate differentiated needs (e.g., 10 items or less). Multiple queues deter balking because lines look smaller than they would if there were only a single queue.
- Single queue: One line; the first person in line receives service next when a server becomes available. This ‘first come, first served’ arrangement typically seems fairest to customers, who are less likely to renege once they are no longer the last person in line. Single queue alleviates customer anxiety over “which line is faster?” Single queue typically reduces customers’ average wait time.
- Take a number: In this variant of the single-queue system, arriving customers take a number to indicate their place in line. No formal line forms. Customers can wander around and shop while waiting to be called for service.
- Virtual queue: Used for telephone-based service, an automated queuing system that informs customers approximately how long they will wait for service.
Queue disciplines
The queue disciplines specify the order in which jobs in the queue are served. Experts typically identify seven disciplines.
- FIFO, First in, first out is the most common discipline. First to arrive is first served; whomever has waited longest gets served next. Customers regard the system as ethical and thus prefer it to other systems. FIFO also applies to retail and raw material consumption.
- LIFO: Last in, first out typically applies to inventory management. LIFO allows businesses to expense recently produced and sold items as cost of goods sold (COGS) while treating older items as inventory. LIFO typically reduces profits but also produces a tax benefit; businesses apply LIFO when it results in a greater net gain.
- Processor sharing serves all entities simultaneously by sharing the available resource. Sometimes called ‘egalitarian processor sharing,’ all clients receive a fraction of available capacity. So long as capacity exceeds demand—as it typically does on, say, a commercial website—all customers receive immediate service. When demand exceeds capacity, delays impact most or all users, e.g., the Taylor Swift Ticketmaster fiasco.
- Priority scheduling generally follows FIFO, with the exception that some entities are assigned high-priority numbers that allow them to ‘jump the line.’ Consider a doctor’s office in which patients are served in the order of their appointments, *except* when an emergency arrives. If the doctor interrupts his current session to attend the emergency case, the process is described as *pre-emptive*; if the doctor completes the session and then attends to the emergency, the process is described as *non-pre-emptive*. In the same way, CPU scheduling may prioritize tasks, allowing certain critical tasks to jump the line in either a pre-emptive or non-pre-emptive manner, depending on the operative algorithm.
- Shortest job first (SJN) is a non-pre-emptive algorithm where the priority is based on the execution time, also known as ‘burst time.’ In this case, the shorter the duration, the higher the priority of the task. This ‘low-hanging fruit’ approach is frequently employed in CPU scheduling, especially when many processes arrive at the processor simultaneously.
- Pre-emptive shortest job first disrupts the current process when a process of shorter duration arrives. The goal is to reduce overall waiting time and allow faster completion for shorter processes. However, this method is possible only if the processor has knowledge about the burst time for the process. This is not a recommended method if too many short duration processes arrive between longer duration processes, since it will lead to long waiting time or ‘starvation’ for the longer processes.
- Shortest remaining processing time is a pre-emptive CPU scheduling process under which the processing time of an arriving process is compared with the remaining time of the current process. Whichever process requires less time is completed first. This discipline can be exercised only if the estimated burst time for the processes is known. The advantage of this method is that a current process that has already executed partially and is closer to completion than a new one can be allowed to complete.
Service process
The distribution of service times, arrangement of servers, number of servers, management policies, and server behavior all contribute to service performance. Service time can be a constant, such as the amount of time to wash a car through an automated car wash. However, service time typically is not a constant. Consider the examples of a fast-food service window or a toll booth at a bridge. The distribution of service times reflects the variation in customer needs and server performances.
.
Questions or feedback? Email editor@noodle.com
About the Editor
Tom Meltzer spent over 20 years writing and teaching for The Princeton Review, where he was lead author of the company's popular guide to colleges, before joining Noodle.
To learn more about our editorial standards, you can click here.







